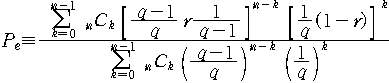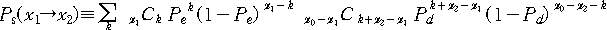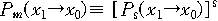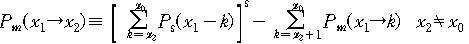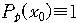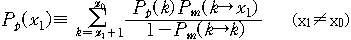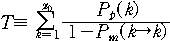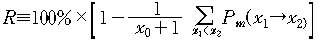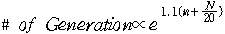......전 우주에 걸쳐 1/1050 보다 낮은 확률은 일어날 수 없다......L-아미노산들이 각 단백질마다
독특 한 한가지 배열을 해야만 그 단백질의 기능을 수행할 수 있는데 100개의
L-아미노산들이 우연히 특정한 배열을 할 수 있는 확률은 1/10130이다......1)
그리고 이어서 전체 생명체 수준은 훨씬 복잡하며 따라서 그것이 우연에 의해 생길
수는 없다는 주장이 따라나온다. 100개의 아미노산이 특정한 배열을 이룰 확률은
필수 아미노산이 20가지가 있으므로 1/20100에 해당하게 된다. 2010=1024≒103이라고
보면 위 확률은 1/20100=1/(2100×10100)≒1/(1030×10100)=1/10130 로 얻어진다. 146개의 아미노산을 가지고 있는 헤모글로빈의 경우 확률값은
대략 1/10190로 얻어진다.
헌신된 진화론자인 Richard Dawkins는 『눈먼 시계공(The Blind Watchmaker)』이라는
대단히 유명한 책을 썼다. 어떤 저자들은 아직도 설계논증에 '집착'하고 있는 사람들에게
이 책을 권하기도 한다.2)
Dawkins는 이 책의 3장에서 헤모글로빈의 확률에 관해 언급하고 나서 창조론자들의
논의에 반론을 제기하기 시작한다. 그는 우선 '일단계 선택'과 '누적적 선택'을 구별한다.
일단계 선택에서는 한 번에 전체가 선택되지만 누적적 선택에서는 선택의 결과가
다음으로 계속 이어져서 누적된다. Dawkins가 하고자 하는 말은 위에서의 확률은
(매번 젼혀 새로운 시도를 하는) 일단계 선택에나 적용되는 것이지 (비록 작기는
하지만 매번의 개선이 미래를 건설하는 기초가 되는) 누적적 선택에는 적용되지 않는다는
것이다. 한편 보다 흥미로운 것은 Dawkins가 누적적 선택의 효과를 보여주는 간단한
컴퓨터 프로그램의 결과를 보여주고 있다는 것이다. 'METHINKS IT IS LIKE A WEASEL'이라는
문장을 일단계 선택을 통하여 얻을 확률은 대략 1/1040으로 계산되었다. 누적적 선택을 골자로 하는 프로그램에 의해 얻어진
결과의 한 예는 다음과 같았다.
WDLDMNLT DTJBKWIRZREZLMQCO P 시작
WDLTMNLT DTJBSWIRZREZLMQCO P 1세대
MDLDMNLS ITJISWHRZREZ MECS P 10세대
MELDINLS IT ISWPRKE Z WECSEL 20세대
METHINGS IT ISWLIKE B WECSEL 30세대
METHINKS IT IS LIKE I WEASEL 40세대
METHINKS IT IS LIKE A WEASEL 43세대
겨우 43세대만에 원하는 문장이 얻어졌고, 반복된 시행에서도 크게 다르지 않았다.
이러한 결과는 앞에서 말하였던 창조론자들의 주장을 간단히 뒤집는 것처럼 보인다.
Dawkins에 따르면 '다윈의 조리법 에서 확률은 별볼일 없는 양념이다. 반면에 가장
중요한 요소는 절대로 무작위적이지 않은, 누적적인 선택이다.' 그의 주장은 확실히
설득력이 있어 보이고 누적적 선택은 작은 확률의 어려움을 충분히 극복할 수 있는
것처럼 보인다. 그는 '만약 진화가 일단계 선택에 의존해야 했다면 전혀 불가능했을
것이다. 그러나 누적적인 선택에 필요한 조건이 자연의 맹목적인 힘에 의해 성립될
수 있는 어떤 방법이 있었다면, 그 과정은 가능했을 것이다. 실제로 그것이 바로
이 지구라는 행성에서 일어난 일이다'라고 썼다.3)
이에 대해서 창조론자들이 종종 제기하는 반론은 그러한 결과를 만들어낸 프로그램(software)도
컴퓨터(hardware)도 지적인 존재가 설계했다는 것이다. 따라서 이 프로그램의 결과도
지적 설계의 산물이 므로 '생명체가 우연의 산물'이라는 주장의 근거로 사용될 수
없다는 것이다. 일견 이것은 날카로운 지적인 듯 보인다. 그러나 좀 더 생각해보자.
말하자면 hardware는 우주에, software는 법칙에 비교할 수 있겠다. 따라서 지적
설계에 의해서건 아니건 적절한 조건을 갖춘 우주와 법칙이 주어지면 그 이후에는
외부로부터 다른 개입 없이 생명이 탄생할 수 있다는 얘기가 된다. 컴퓨터의 난수발생이
과연 임의적 (random)인가 하는 질문도 생각해 볼 수 있지만 Dawkins의 목적에 비추어서는
충분히 임의적이다. 왜냐하면 Dawkins는 진정한 의미에서의 임의성을 원한 것이 아니라
다만 그것이 최종 목적지를 염두에 두지 않는다는 의미에서만 임의적인 것을 원하였기
때문이다. 확실히 프로그램은 Dawkins의 지성의 개입하에 그의 의도대로 작성되었다.
그러나 그의 의도라는 것은 그 안에서 임의적인 돌연변이와 자연선택이 일어나게
하는 것이었고, 실제로 그렇게 되었다. 이러한 이유들 때문에 프로그램과 컴퓨터가
지적 설계의 산물임을 지적하는 것은 그다지 효과적인 반론이 되지 못한다. 오히려
그것은 하나님께서 모든 생물이 자연선택을 통해 발생하도록 초기 조건과 법칙을
마련하신 후 간섭하지 않으신다는 견해로 연결되기 쉽다. 이는 이신론으로서 '살아계셔서
역사하시는 하나님'에 정면으로 배치되는 견해이다. 자연주의 자들도 이신론에는
비교적 관대한데 그들도 이신론이 자신들의 입장에 그다지 위협적이지 않다는 사실
을 알고 있기 때문이다.
또 한 가지 반론은 결과적으로 얻은 문장인 'METHINKS IT IS LIKE A WEASEL'이 처음부터
주 어져 있었으므로 (그렇지 않았다면 여러 문장 중 이 문장과 좀 더 비슷한 문장을
선택할 수가 없었을 것이다.) 이 문장이 우연과 자연선택에 의해서 '생성'되었다고
볼 수 없다는 것이다. William Dembski는 이와 관련하여 다소 세련된 논의를 폈다.4)
Dembski는 Dawkins의 알고리즘으로 목표한 문장 외에 무었을 달성할 수 있는지 묻는다.
항상 목표 한 문장을 얻을 뿐이다. 따라서 목표한 문장이 얻어질 확률은 알고리즘이
진행되면서 점점 커져서 1로 수렴하게 된다. 즉 Dawkins의 알고리즘은 확률 증폭기(probability
amplifier)라는 것이다. 그러나 확률 증폭기는 복잡성 감쇠기(complexity attenuator)이다.
확률이 1로 수렴할 때 정보 또는 복잡성은 0으로 수렴하게 된다. 따라서 이 알고리즘으로는
특수화된 복잡성(specified complexity)이 생성될 수 없다는 것이 Dembski의 주장이다.
부언하자면, 얻어진 문장은 분명 특수화된 복잡성을 가지고 있는 것으로 보이지만
알고리즘으로는 그것이 생성될 수 없고 애초에 프로그램에 그 문장을 주어질 때 특수화된
복잡성 역시 주어져서 그것 이 알고리즘을 통하여 결과로 나타 났다고 볼 수 있겠다.
그러나 이러한 견해도 또한 이신론을 피하는 데에는 충분치 못하다. 그 점을 살 펴보기
전에 먼저 생각해 볼 것이 있다.
그림 1. 유전자 공간에서의 바이오모프들 ("눈먼시계공"의
3장에서 발췌)
그림 1을 보자. 이 그림은 "눈먼 시계공"에 나오는
그림으로 Dawkins가 바이오모프(biomorph) 라고 부르는 것들이 그려져 있다. 그것들은
유전자에 해당하는 정보 에 의해서 생성되도록 프로그래밍 되었는데 그 정보는 돌연변이를
할 수도 있도록 되어 있다. 그림에서 위치 관계를 주목해보라. 두 바이오모프 사이의
거리는 하나에서 다른 하나로 변할 때에 필요한 최소의 돌연변이 수와 비례하게 그린
것 이다. 사실 이렇게 하려면 더 높은 차원이 필요하지만 (이 경우 9차원) 그런 높은
차원은 그릴 수가 없 으므로 2차원에 그린 것이다.
원래의 높은 차원을 가진 공간을 생각해보자. 그리고 바이오모프가 아닌 실제 생물을
생각하자. 이 공간 위에 생존에 대한 적합성을 나타내는 어떤 함수가 정의된다고
상상해보자. 그리고 임의의 한 점을 택하여 Dawkins의 알고리즘을 수행한다고 해보자.
먼저 돌연변이를 가진 자손들은 시작점 주위로 흩어 져 있는 점으로 나타날 것이다.
그리고 그것들 중에서 함수값이 가장 큰 것이 선택될 것이다. 그리고 다 시 돌연변이를
가진 자손들이 나타난다. 이런 과정이 계속 된다면 의심의 여지없이 점들은 점차로
주위 에 있는 극대값에 접근하게 될 것이다. 이러한 알고리즘은 실제로 어떤 함수의
극대값(또는 극소값)을 구하는 데에 실제로 사용된다.
태초에 유전자 공간과 함수가 주어졌다고 생각할 수도 있다. 그에 해당하는 생물이
출현하기 전이 라도 공간과 함수 자체는 주어졌다고 생각하지 않을 이유가 없다.
그리고 당연히 함수의 극대값도, 극대 값에서의 유전자도, 주어져 있을 것이다. 그리고
Dawkins의 알고리즘으로 극대값에서의 유전자를 가진 생물이 출현하였을 수 있다.
이것은 처음에 문장을 프로그램에 쳐 넣는 것과 다를 바가 없다.
Dembski도 확실히 이 점을 이해하고 있었다. 그는 Dawkins의 알고리즘이 생성해 낸
것이 실제적인 특수화된 복잡성이 아니라 외형상의 특수화된 복잡성이라고 논하였지만
생물이 실제적인 특수화된 복잡 성을 가지고 있는지에 대한 것은 별개의 문제라고
말한다. 그리고 거기서 그는 논점을 Michael Behe에게 넘겨버린다.
Behe는 그의 유명한 책 『Darwin's Black Box』에서 환원 불가능한 복잡성(irreducible
complexity)이라는 개념을 이야기하였다. 어떤 기능을 하는 시스템이 여러 부분으로
이루어져 있는데, 그 중의 한 부분을 제거하면 시스템의 기능이 완전히 정지하는
경우 이 시스템은 환원 불가능하게 복잡 한 것이다. 환원 불가능한 복잡성을 가진
시스템은 Dawkins의 알고리즘으로는 생성될 수 없다. 완전한 상태에 이르기 전의
어떠한 상태도 전혀 기능을 하지 못하므로 누적적 선택을 통하여 이 시스템이 생성
될 수는 없는 것이다. Behe는 수많은 생화학적 시스템들이 환원 불가능하게 복잡하며
따라서 Dawkins 의 알고리즘을 통해서는 생성될 수 없다고 주장한다.
Behe와 Dawkins는 정반대의 주장을 하고 있다. 이렇게 정반대의 주장이 맞설 때에는,
경우에 따라서는, 흑백논리식으로 접근하였다가는 자칫하면 소모적이고 비생산적인
논쟁을 벗어나지 못할 수도 있 고 한쪽에서 지적한 중요한 점들을 완전히 놓쳐버릴
수도 있다. 물론 경우에 따라서는 흑백논리가 옳을 수도 있을 것이다. 그러나 어떤
경우에는 두 경우를 각각 반대쪽 극한으로 갖는 일반이론을 수립하는 것이 유익할
수도 있다. 예를 들어 여기에 서로 반대되는 이론 와 A와 B가 있다고 하자. A가 옳으냐,
B가 옳으냐 하는 논쟁을 벌일 수도 있다. 그러나 어떤 이론 C를 수립하여서 거기에서
어떠한 변수 x를 정의하여서 x=0일 때는 A와 같아지고 (C{x=0}=A) x=1일 때는 B와
같아지게 (C{x=1}=B) 하면 x의 값이 실제로 얼마인가를 구하는 문제로 바꾸어 접근할
수도 있는 것이다. Dawkins와 Behe의 견해를 각각 A와 B라고 할 때 C는 어떤 형태가
될 수 있으며, 그 때의 x는 어떤 값일까? Dawkins가 무시하고 있는 측면은 무엇일까?
내가 보기에 Dawkins의 실수는 선택의 단위를 변이의 단위와 같게 놓은 데에 있다.
프로그램에서 돌연변이는 한 글자를 단위로 일어난다. 자연선택 또한 한 글자를 단위로
일어난다. 그러나 실제 생물은 어떠한가? 돌연변이는 DNA 염기 하나를 단위로 해서
일어난다.5) 하지만 자연선택은
명백히 DNA 염기 하나를 단위로 하지는 않는다. 염기 셋이 모여야 비로소 아미노산
하나가 결정된다. 아미노산 하나(즉 염기 셋)도 일반적으로 자연선택의 단위가 되기는
어렵다.6) 자연선택의
단위는 그보다 훨씬 클 것이다. 요컨대 실제의 경우라면 선택의 단위는 변이의 단위와는
매우 다르다.
선택의 단위가 변이의 단위에 비하여 얼마나 큰가 하는 것이, 말하자면, 일반이론
C에서의 x에 해 당한다. Dawkins의 입장은 선택의 단위가 변이의 단위가 같은 한쪽
극단의 경우이며 Behe의 입장은 선 택의 단위가 변이의 단위에 비해 무지막지하게
크기 때문에 도무지 돌연변이와 자연선택을 통한 진화로 는 도무지 설명할 수 없다는
다른 쪽 극단의 경우이다. 그러면 일반이론을 세우고 선택의 단위의 크기 에 따라
진화하는 데에 걸리는 시간에 어떠한 영향을 미치는지 살펴보고 또 실제의 경우에
선택의 단위 의 크기가 얼마인지 구해볼 수 있을 것이다.
이 글에서 보고하게될 작업은 이러한 일반이론을 구성하고자 하는 시도의 일부이다.
이를 위해서 나는 Dawkins의 프로그램을 다소 개선하였다. 사실은 Dawkins가 어떻게
프로그램을 짰는지 정확히는 모른다. 그러나 Dawkins가 설명한대로 프로그램을 작성하였으며
(언어도 Dawkns와 마찬가지로 BASIC 을 사용하였다) 결과도 비슷하였으므로 그것이
Dawkins의 프로그램과 실질적으로 같다고 생각하였다.
변이의 단위는 글자 하나로 그대로 두었다. 그러나 선택의 단위는 사용자가 임의로
선택할 수 있도 록 두었다. 그것은 글자 둘로 선택할 수도 있고 셋으로 선택할 수도
있다. 이 프로그램과 함께 주어진 조건에서 목표하는 문장에 도달하는 데에 몇 세대나
걸릴지를 예측할 수 있는 이론을 세워 이것을 계산 하는 프로그램도 작성하였다.
Simulation
simulation 프로그램은 먼저 목표하는 문장과 시작할 문장을 입력 받고, 선택의 단위
- irreducible unit이라 부르기로 한다 - 와 돌연변이율, 그리고 한 세대의 개체수를
입력받는다. 그런 다음 시작하는 문장으로부터 돌연변이율에 따라 약간씩 달라진
문장들을 입력받은 개수만큼 생성한다. 그런 다음 irreducible unit만큼씩 잘라서
목표하는 문장과 비교한다. 그래서 가장 많은 수의 도막이 일치하는 문장 이 선택된다.
그리고 이 과정을 목표하는 문장과 완전히 동일한 문장이 나올 때까지 반복한다.
그리고 물론 이 과정이 몇 세대만에 이루어졌는지를 센다. 같은 simulation을 반복시킬
수도 있으며 중간과정을 볼 수도 있다.
Calculation
simulation을 특징짓는 다섯 개의 변수가 있다. 문장의 길이, irreducible unit,
돌연변이율, 한 세대의 개체수 그리고 한 글자가 가질 수 있는 경우의 수(이 경우에는
알파벳 26개와 띄어쓰기까지 27이 된다) 가 그것이다. 이것들을 각각 N, n, r, s,
q로 나타내기로 하자.
n개의 글자로 이루어진 문자도막을 생각하자. 이 부분이 목표하는 문자열의 그 부분과
일치하였다고 하자. 이 일치가 그대로 유지될 확률은 (1-r)n 일 것이다. 따라서 돌연변이에 의해서 목표하는 문자 열과 달라질 확률은Pd=1-(1-r)n 이 된다. 한편 문자도막이 목표하는 문자열의 그 부분과 일치하지 않다가
돌연변이를 통해 일치할 확률은 다음과 같이 구할 수 있다.
이때 k는 n개의 문자중 목표문자열과 같은 것의 개수이다. 이를
정리하면 Pe=Pd/(qn-1)이 됨을 알 수 있다.
이제 x라는 변수를 정의하자. x는 어떠한 문자열에 대해서 정의되는데 n개의 문자로
이루어진 각각의 도막들 중에 목표문자열과 일치하지 않는 도막의 수이다. x0는 x0
= N/n으로 정의되며 처음에 x=x0에서 시작하여 점점 줄어들어서 x=0에 도달하면 목표문자열에
도달한 것이다. 문자열의 x값이 돌연변이를 통하여 x1에서 x2로 바뀔 확률은 다음과
같다.
이것은 하나의 문자열이 하나의 자손만을 가질 때에 해당하는
확률일 것이다. 그러면 s개의 자손을 가지고 그 중에서 선택될 것의 x값만을 생각하면
그 확률은 다음과 같이 된다.
문자열이 진화하면서 x=x0에서 x=0까지 가는 동안 특정 x값을
가지는 상태를 거칠 확률은 다 음과 같이 주어진다.
그리고 마지막으로 목표문자열까지 도달하는데 걸리는 세대수는
다음과 같은 꼴을 가지게 된다.
이와 같은 계산을 하는 프로그램을 작성하였다. simulation 프로그램과
구분하기 위하여 이 프로그 램을 calculation 프로그램이라고 부르기로 하겠다. 이
프로그램은 두 가지 근사를 한다. 첫째로 계산 도중에 10-45이하의 확률은 모두 0으로 간주한다. 이것은 의도된 것은 아니고 컴퓨터가
스스로 그렇게 하였다. 둘째는 원래 식을 얻을 때부터 한 근사로서 x1 < x2일
때는 Pm(x1→x2=0이라고 보았다. 실제 이 값을 계산할 수는 있다. 그러나 그 이후의 계산에서는
0으로 보고 풀 수밖에 없었다. 무시된 확률이 얼마인지 다음과 같은 식으로 계산할
수도 있다.
이때 R값이 100%에 가까울수록 무시된 확률은 작은 값들인 것이다.
이후 사용한 모든 계산값들에 있어서 R값은 99.999% 이상이었다.
Results & Discussions
먼저 simulation 프로그램과 calculation 프로그램이 제대로 작동하는지 점검할 필요가
있을 것이다. 이와 아울러 이후에 사용할 돌연변이율과 한 세대의 개체수를 정하기
위하여 Dawkins가 사용한 문장 "METHINKS IT IS LIKE A WEASEL"을 목표문자열로
삼고 돌연변이율과 한 세대의 개체수를 변화 시키면서 simulation과 calculation을
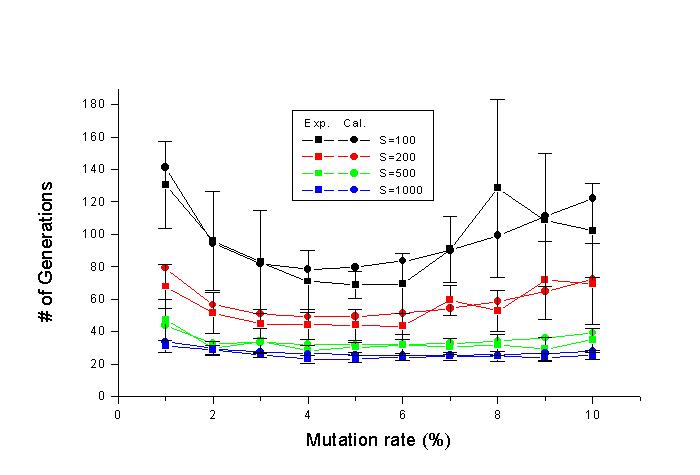
하였다. 그 결과를 그림 2에 나타내었다. 이때 irreducible unit은 1 로 놓았다.
그림 2. "METHINKS IT IS LIKE A WEASEL"을
목표문자열로 하고 irreducible unit은 1로 놓고 돌연변이율은 1%부터 10%까지, 한
세대의 개체수는 100, 200, 500, 1000으로 변화시키면서 simulation과 calculation을
수행하였다. 사각형은 simulation, 원은 calculation 결과이다.
그림 2에서 보면 simulation 프로그램의 결과와 calculation 프로그램의
결과가 잘 일치하는 것을 볼 수 있다. 또, 한 세대의 개체수가 500이나 1000일때는
Dawkins의 경우보다 더 빨리 목표문자열에 도달 한다. 그러므로 적어도 Dawkins의
프로그램만큼은 작동한다고 생각할 수가 있겠다.
돌연변이율 5% 근처에서 극소값이 생기고 돌연변이율이 아주 작아지거나 아주 커지면
목표문자열 에 도달하는데 더 많은 세대가 걸리는 것을 알 수 있는데, 작을 때는
선택될 돌연변이의 수가 적기 때 문이고 클 때는 돌연변이가 누적된 선택의 결과를
해치는 경향이 많아지기 때문이다. 이하 모든 simulation과 calculation에서는 돌연변
이율 5%와 한 세대의 개체수 200을 사용하였다. 돌연변이율은 진화가 가장 빠른 값을
택한 것이며, 한 세대의 개 체수가 200일 때 Dawkins의 결과와 비슷하다고 보아서
이 값을 선택하였다. 100일 때는 너무 많은 세대 수가 걸리고 500이나 1000은 많은
개체를 계산하여야 하기 때문에 simulation하 는 데에 시간이 너무 많이 걸린다.
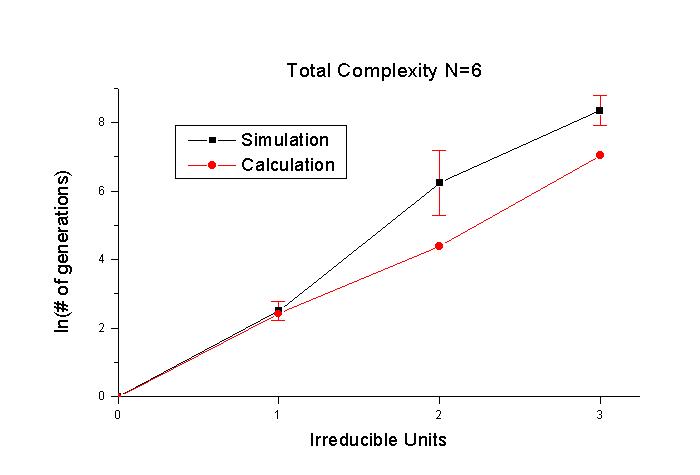
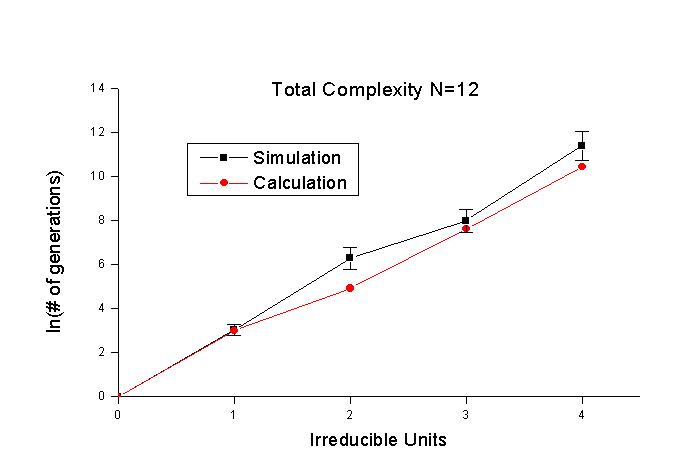
그림 3과 그림 4는 irreducible unit을 변화시켜 본 것이다. 두 경우 모두 세대수에
로그를 취한 것이 irreducible unit에 대해서 직선에 가까 운 형태를 이룬다. 따라서
세대수는 irreducible unit이 증가함에 따라 지수 함수적으로 증가하게 된다. calculation
은 irreducible unit이 1보다 클 때에는 simulation과 다소의 차이를 보이기는 하지만
대체로 비슷한 경향을 보인다. irreducible unit이 커지면서 simulation 을 하는
데 걸리는 시간이 급격히 늘 어난다. 그림 4에서 irreducible unit이 4인 경우 simulation이
한 번 돌아가는 데에 하루가 꼬박 걸린 적도 있다. 이 러므로 irreducible unit이
더 넓은 영 역에서 어떻게 변하는지를 simulation 으로 보는 데에는 현실적인 어려움이
있다. 그래서 calculation이 simulation 과 일치한다고 가정하고 calculation의 결과를
가지고 이야기하는 방향으로 갈 수밖에 없을 것이다.
그림 3. 목표문자열은 "CHRIST"이며 돌연변이율
5%, 한 세대의 개체수 200으로 irreducible unit에 따른 변화를 log-plot으로 나타내었다.
사각형은 simulation, 원은 calculation이다.
그림 4. 목표문자열은 "I LOVE JESUS", 돌연변이율
5%, 한 세대의 개체수 200, irreducible unit을 변화시키면서 log-plot을 하였다.
사각형은 simulation, 원은 calculation이다.
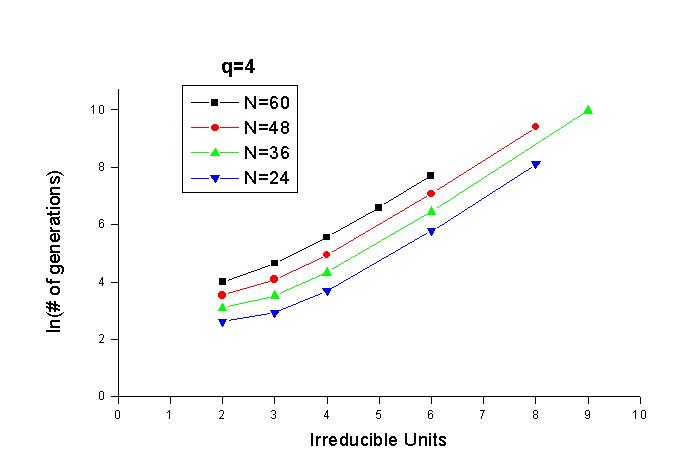
그림 5는 q=4로 놓고 irreducible unit과 문장의 길이를 변화
시키면서 얻은 결과를 로그로 나타낸 것이다. q=4로 놓은 것은 특별한 의미가 있는
것은 아니나, q를 너무 크게 하면 irreducible unit이 커짐에 따라 Pe가 급격히 작아지고,
그 에 따라 오차가 크게 발생하거나 아예 계산을 못할 수도 있기 때문에 작은 값을
택한 것이다. DNA의 경우 q=4이기 때문이기도 하다. 그림 5를 보면 irreducible unit이
3보다 큰 부분에서는 거의 직선에 가까운 형태가 보이는 것을 알 수 있다. 그리고
문장의 길이가 일정하게 늘어남에 따라 직선도 일정한 양만큼 위로 올라가는 것을
또한 볼 수 있다.
그림 5. q=4, 돌연변이율 5%, 한 세대의 개체수 200에서
irreducible unit과 문장의 길이를 변화시키며 log- plot을 한 것이다.
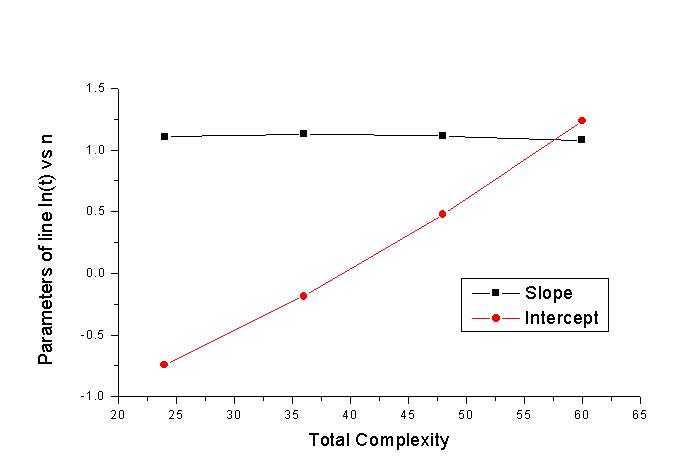
그림 6. 그림 5에서 irreducible unit이 4 이상인 부분들의
직선의 방정식의 기울기 및 y절편이다. 사각형이 기울기이며 원이 y절편이다.
이 직선들의 기울기와 y절편을 각각 구하여 문장의 길이에 대해서
그래프를 그릴 수 있을 것이다. 그것을 그림 6에 나타내었다. 기울기는 대략 일정한
값(∼1.1)에 머무르지만 y절편은 직선을 이루며 변 화한다. 기울기가 머무르는 값과
y절편이 이루는 직선의 자료로부터 다음의 식을 얻어낼 수가 있었다.
이때 n은 irreducible unit이며 N은 문장의 길이이다. 식에서
보면 n이 N보다 20배나 더 중요하게 작용한다. irreducible unit은 매우 중요한 인자
다. 다시 말해서 실제 생물체에서 변 이의 단위와 선택의 단위가 다르다는 점은 매우
중요하다. Dawkins는 중요 한 요점을 놓쳤던 것이다.
위의 식은 q=4, r=5%, s=200인 경우에만 해당된다. 이 값들이 달라지면 n과 N사이의
비도 달라질 것이다. 또한 이 식은 좁은 범위에서 n값과 N값이 변할 때의 결과 로부터
나온 것이므로 그 범위 밖으로 외삽(extrapolation)하는 것은 적절치 않을 수 있다.
Conclusion
Dawkins가 제시한 알고리즘과 그 의 프로그램에 대한 몇 가지 반론을 살펴보았는데
그것들은 이신론을 피하 기 어렵다는 것을 알 수 있었다. Behe 가 환원 불가능한
복잡성의 개념을 통 하여 폈던 반론이 현실적으로 가장 의 미가 있는 것이었다. Dawkins와
Behe 의 견해를 살펴봄에 있어서 그 두 경우를 양쪽 극단의 경우로 갖는 일반 이론을
구성하는 것이 의미가 있을 수 있다는 점을 논하였다.
변이의 단위와 선택의 단위를 같게 취급한 것이 Dawkins의 프로그램에서 잘못된 부분이었다.
실제 생물에서는 그렇지 않다. 그리고 그 단위가 다르다는 것이 결과에 매우 큰 영향을
줄 수 있다는 것을 보았다. 선택의 단위의 크기가 얼마인가에 따른 결과를 말해주는
일반이론을 세울 수 있을 것이다.
이 작업은 이러한 일반이론의 가능성을 보여주며 그 기초를 세우고자 한 시도로 간주될
수 있을 것 이다. 그러나 이 작업은 자체로는 많은 한계를 가지고 있으며, 따라서
일반이론을 세우려면 더 많은 작 업이 뒤따라야만 할 것이다. 먼저 제한된 영역에서만
결과를 얻었으므로 더 이상의 작업이 없이는 위험 하게 다른 영역으로 외삽할 수
없을 것이며, calculation 체계 자체도 개선의 여지가 있을 수 있다. 그리고 이 작업에서는
시스템의 두 부분이 완전히 연관되어 있거나 또는 전혀 연관되지 않은 경우만을 다루게
되는데 실제의 경우 그 사이에 해당하는 경우가 있을 수 있다.
Notes
1) 한국창조과학회 편, "진화는 과학적 사실인가?", 1981, p. 28.
2) John Gribbin; Martin Rees, 오근영 역, "우주 진화의 수수께끼", 푸른
미디어, 1999, p. 288.
3)Richard Dawkins, 과학세대 역, "눈먼 시계공", 민음사, 1994, pp. 73-80.
4) William A. Dembski, "Explaining Specified Complexity", 또한 이에
대한 번역이 SCR 홈페이지에 "특수화된 복잡성 설명하기"라는
제목으로 올라와 있다.
5) 이 말에 이의를 제기하는 사람이 많을 것이다. 실제로 돌연변이 중에는 어느 정도
길이의 서열이 통째로 복사되어 삽입된다든지, 삭제된다든지, 역전된다든지 하는
것들이 있다. 그러나 어떤 새로운 서열이 형성되는 과정을 생각할 때에는 이러한
돌연변이들은 시작점을 제공하는 것 이외에 다른 역할을 할 수 있다고 보기 어려울
듯 하다.
6) 아미노산 하나가 바뀌어서 자연선택에 영향을 주는 예들도 있다. 유명한 겸상
적혈구 빈혈증(sickle cell anemia)도 한 예일 것이며, 세균이 약에 대해 내성을
가지는 것도 약이 inhibit하는 효소의 active site에서 아미노산 하나가 바뀌었기
때문인 사례가 있다. 그러나 이는 명백히 아주 새로운 서열을 만드는 과정에서 새로운
서열이 나타내는 기능으로부터 나오는 자연선택에 미치는 영향을 다룰 때와는 전혀
다른 문제이다.













 Simulating Irreducible Complexity (김창환)
Simulating Irreducible Complexity (김창환)